import pandas as pd
df = pd.DataFrame( {"林大明":[65,92,78,83,70], "陈聪明":[90,72,76,93,56], "黄美丽":[81,85,91,89,77], "熊小娟":[79,53,47,94,80] } )
print(df)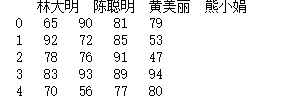
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print(df)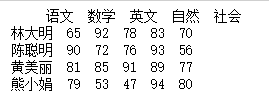
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)indexs[0] = "林晶辉"df.index = indexscolumns[3] = "理化"df.columns = columnsprint(df)
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print('df["自然"] ->')print(df["自然"])print()print('df[["语文", "数学", "自然"] ->')print(df[["语文", "数学", "自然"]])print()print('df[df.数学>=80] ->')print(df[df.数学 >= 80]) 
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print("df.values:")print(df.values)print("陈聪明的成绩(df.values[1]):")print(df.values[1])print("陈聪明的英文成绩(df.values[1][2]):")print(df.values[1][2])
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print(df)print('df.loc["陈聪明", :] ->')print(df.loc["陈聪明", :])#print(df.loc["陈聪明"])print()print('df.loc["陈聪明"]["数学"] ->')print(df.loc["陈聪明"]["数学"])print()print('df.loc[("陈聪明", "熊小娟") ->')print(df.loc[("陈聪明", "熊小娟"), :])print()print('df.loc[:, "数学"] ->')print(df.loc[:, "数学"])print()print('df.loc[("陈聪明", "熊小娟"), ("数学", "自然")] ->')print(df.loc[("陈聪明", "熊小娟"), ("数学", "自然")])print()print('df.loc["陈聪明":"熊小娟", "数学":"社会"] ->')print(df.loc["陈聪明":"熊小娟", "数学":"社会"])print()print('df.loc[:黄美丽, "数学":"社会"] ->')print(df.loc[:"黄美丽", "数学":"社会"])print()print('df.loc["陈聪明":, "数学":"社会"] ->')print(df.loc["陈聪明":, "数学":"社会"])
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print(df)print('df.iloc[1, :] ->')print(df.iloc[1, :])print()print('df.iloc[1][1] ->')print(df.iloc[1][1])
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print(df)print('陈聪明的数学科成绩 ->')print(df.ix["陈聪明"]["数学"])print(df.ix["陈聪明"][1])print(df.ix[1]["数学"])print(df.ix[1][1])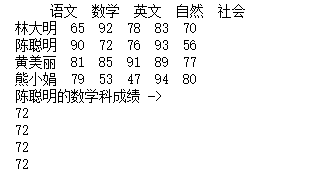
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print(df)print('最前 2 位学生成绩 ->')print(df.head(2))print()print('最后 2 位学生成绩 ->')print(df.tail(2))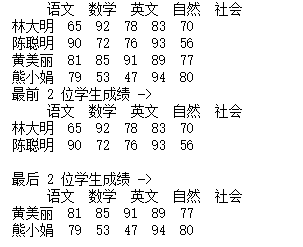
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print(df)print('df.ix["陈聪明"]["数学"] (原始):' + str(df.loc["陈聪明"]["数学"]))df.ix["陈聪明"]["数学"] = 91print('df.ix["陈聪明"]["数学"] (修改):' + str(df.loc["陈聪明"]["数学"]))print()print('df.ix["陈聪明", :] ->')df.ix["陈聪明", :] = 80print(df.ix["陈聪明", :])
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print(df)print('按照数学成绩降序排序 ->')df1 = df.sort_values(by="数学", ascending=False)print(df1)print()print('按照列标题升序排序 ->')df2 = df.sort_index(axis=0)print(df2)print()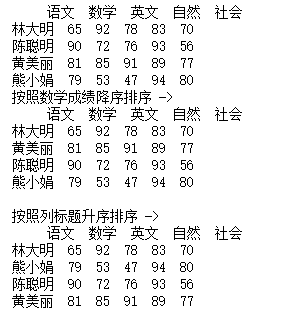
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)print(df)print('删除陈聪明成绩 ->')df1 = df.drop("陈聪明")print(df1)print()print('删除数学成绩 ->')df2 = df.drop("数学", axis=1)print(df2)print()print('删除数学及自然成绩 ->')df3 = df.drop(["数学", "自然"], axis=1)print(df3)print()print('删除从陈聪明到熊小娟成绩 ->')df4 = df.drop(df.index[1:4])print(df4)print()print('删除从数学到自然的成绩 ->')df5 = df.drop(df.columns[1:4], axis=1)print(df5)print()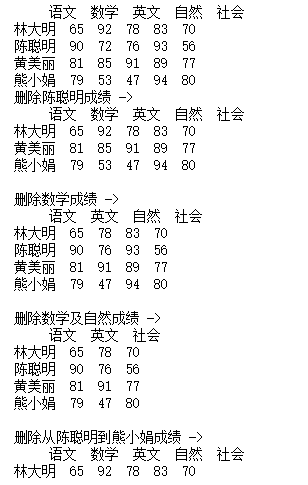
import pandas as pd
dt = pd.read_html("http://www.86pm25.com/city/beijing.html")
data=dt[0]print(data)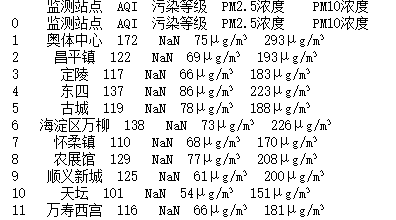
import pandas as pd
tables = pd.read_html("http://value500.com/M2GDP.html")
n = 1for table in tables: print("第 " + str(n) + " 个表格:") print(table.head()) print() n += 1
import pandas as pd
tables = pd.read_html("http://value500.com/M2GDP.html")
table = tables[18]table = table.drop(table.index[0:1])table.columns = ["年份", "M2指标", "GDP绝对额", "M2/GDP"]table.index = range(len(table.index))print(table)import pandas as pd
from pylab import *rcParams['font.sans-serif'] = ['SimHei'] #设置中文显示datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]columns = ["语文", "数学", "英文", "自然", "社会"]df = pd.DataFrame(datas, columns=columns, index=indexs)df.plot()
def rbCity(): #单击区县按钮的处理函数
global sitelist, listradio sitelist.clear() #清除原有监测站点列表 for r in listradio: #删除原有监测站点按钮 r.destroy() n=0 for c1 in data["监测站点"]: #逐一取出所选区县市的监测站点 if(c1 == city.get()): sitelist.append(data.ix[n, 1]) n += 1 sitemake() #生成测站点按钮 rbSite() #显示PM2.5数值def rbSite(): #单击监测站按钮后的处理函数
n = 0 for s in data.ix[:,1]: #逐一取得监测站点 if(s == site.get()): #如果某监测站点名称与选中的监测站点相同,则 pm = data.ix[n][ "PM2.5浓度"] #取得该站点的PM2.5数值 print(pm) pm=pm[:-5] #去除数据后面的5位单位字符 pm=int(pm) #把PM2.5的字符型数据转为整型 if(pd.isnull(pm)): #如果没有数据,则 result1.set(s + "站的 PM2.5 值当前无数据!") #显示无数据 else: #如果有数据,则 if(pm <= 35): #转换为空气质量等级 grade1 = "优秀" elif(pm <= 53): grade1 = "良好" elif(pm <= 70): grade1 = "中等" else: grade1 = "差" result1.set(s + "站的 PM2.5 值为" + str(pm) + ";" + grade1 ) break #找到选中的监测站点的数据后就跳出循环 n += 1def clickRefresh(): #重新读取数据 global data df = pd.read_html("http://www.86pm25.com/city/beijing.html") data=df[0] rbSite() #更新监测站点的数据def sitemake(): #建立监测站点按钮
global sitelist, listradio for c1 in sitelist: #逐一建立按钮 rbtem = tk.Radiobutton(frame2, text=c1, variable=site, value=c1, command=rbSite) #建立单选按钮 listradio.append(rbtem) #插入至按钮列表 if(c1==sitelist[0]): #默认选取第1个按钮 rbtem.select() rbtem.pack(side="left") #靠左对齐import tkinter as tk
import pandas as pddf = pd.read_html("http://www.86pm25.com/city/beijing.html")
data=df[0]win=tk.Tk()win.geometry("640x270")win.title("PM2.5 实时监测")city = tk.StringVar() #区县名称变量site = tk.StringVar() #监测站点名称变量result1 = tk.StringVar() #显示信息变量citylist = [] #区县列表sitelist = [] #监测站点列表listradio = [] #区县按钮列表#建立区县列表for c1 in data["监测站点"]: if(c1 not in citylist): #如果列表中不存在该县区就将该县区名称插入列表 citylist.append(c1)#建立第1个区县的监测站点列表count = 0for c1 in data["监测站点"]: if(c1 == citylist[0]): #如果是第1个区县,则 sitelist.append(data.ix[count, 1]) #把该区县的所有监测站点插入到监测站点列表 count += 1label1 = tk.Label(win, text="区县:", pady=6, fg="blue", font=("新细明体", 12))label1.pack()frame1 = tk.Frame(win) #区县容器frame1.pack()for i in range(0,2): #按钮分2行 for j in range(0,8): #每行8个 n = i * 8 + j #第n个按钮 if(n < len(citylist)): city1 = citylist[n] #取得区县名称 rbtem = tk.Radiobutton(frame1, text=city1, variable=city, value=city1, command=rbCity) #建立单选按钮 rbtem.grid(row=i, column=j) #设置按钮的位置 if(n==0): #选取第1个区县 rbtem.select()label2 = tk.Label(win, text="监测站点:", pady=6, fg="blue", font=("新细明体", 12))label2.pack()frame2 = tk.Frame(win) #监测站点容器frame2.pack()sitemake()btnDown = tk.Button(win, text="更新数据", font=("新细明体", 12), command=clickRefresh)btnDown.pack(pady=6)lblResult1 = tk.Label(win, textvariable=result1, fg="red", font=("新细明体", 16))lblResult1.pack(pady=6)rbSite() #显示测站讯息win.mainloop()def rbCity(): #點選縣市選項按鈕後處理函式
global sitelist, listradio sitelist.clear() #清除原有測站串列 for r in listradio: #移除原有測站選項按鈕 r.destroy() n=0 for c1 in data["County"] == city.get(): #逐一取出選取縣市的測站 if(c1 == True): sitelist.append(data.ix[n, 0]) n += 1 sitemake() #建立測站選項按鈕 rbSite() #顯示PM2.5訊息def rbSite(): #點選測站選項按鈕後處理函式
n = 0 for s in data.ix[:, 0]: #逐一取得測站 if(s == site.get()): #取得點選的測站 pm = data.ix[n, "PM2.5"] #取得PM2.5的值 if(pd.isnull(pm)): #如果沒有資料 result1.set(s + "站的 PM2.5 值目前無資料!") else: #如果有資料 if(pm <= 35): #轉換為等級 grade1 = "低" elif(pm <= 53): grade1 = "中" elif(pm <= 70): grade1 = "高" else: grade1 = "非常高" result1.set(s + "站的 PM2.5 值為「" + str(pm) + "」:「" + grade1 + "」等級") break #找到點選測站就離開迴圈 n += 1def clickRefresh(): #重新讀取資料 global data# data = pd.read_csv("http://opendata.epa.gov.tw/ws/Data/REWXQA/?$orderby=SiteName&$skip=0&$top=1000&format=csv") data = pd.read_csv("F:\\pythonBase\\pythonex\\ch09\\AQX_20160927145712.csv") rbSite() #更新測站資料def sitemake(): #建立測站選項按鈕
global sitelist, listradio for c1 in sitelist: #逐一建立選項按鈕 rbtem = tk.Radiobutton(frame2, text=c1, variable=site, value=c1, command=rbSite) #建立選項按鈕 listradio.append(rbtem) #加入選項按鈕串列 if(c1==sitelist[0]): #預設選取第1個項目 rbtem.select() rbtem.pack(side="left") #靠左排列import tkinter as tk
import pandas as pd# data = pd.read_csv("http://opendata.epa.gov.tw/ws/Data/REWXQA/?$orderby=SiteName&$skip=0&$top=1000&format=csv")
data = pd.read_csv("F:\\pythonBase\\pythonex\\ch09\\AQX_20160927145712.csv")win=tk.Tk()
win.geometry("640x270")win.title("PM2.5 實時監測")city = tk.StringVar() #縣市文字變數
site = tk.StringVar() #測站文字變數result1 = tk.StringVar() #訊息文字變數citylist = [] #縣市串列sitelist = [] #鄉鎮串列listradio = [] #鄉鎮選項按鈕串列#建立縣市串列
for c1 in data["County"]: if(c1 not in citylist): #如果串列中無該縣市就將其加入 citylist.append(c1)#建立第1個縣市的測站串列count = 0for c1 in data["County"]: if(c1 == citylist[0]): #是第1個縣市的測站 sitelist.append(data.ix[count, 0]) count += 1label1 = tk.Label(win, text="縣市:", pady=6, fg="blue", font=("新細明體", 12))
label1.pack()frame1 = tk.Frame(win) #縣市容器frame1.pack()for i in range(0,3): #3列選項按鈕 for j in range(0,8): #每列8個選項按鈕 n = i * 8 + j #第n個選項按鈕 if(n < len(citylist)): city1 = citylist[n] #取得縣市名稱 rbtem = tk.Radiobutton(frame1, text=city1, variable=city, value=city1, command=rbCity) #建立選項按鈕 rbtem.grid(row=i, column=j) #設定選項按鈕位置 if(n==0): #選取第1個縣市 rbtem.select()label2 = tk.Label(win, text="測站:", pady=6, fg="blue", font=("新細明體", 12))
label2.pack()frame2 = tk.Frame(win) #測站容器frame2.pack()sitemake()btnDown = tk.Button(win, text="更新資料", font=("新細明體", 12), command=clickRefresh)
btnDown.pack(pady=6)lblResult1 = tk.Label(win, textvariable=result1, fg="red", font=("新細明體", 16))lblResult1.pack(pady=6)rbSite() #顯示測站訊息win.mainloop()